smartR AI™和EPCC正在合作使用Cerebras CS-2晶圆级引擎(WSE)系统进行人工智能试验. 迄今为止的结果显示,人工智能的训练时间大幅减少.
ScotlandIS成员, EPCC, 相信下面这篇博客中描述的smartR AI令人印象深刻的结果清楚地证实了Cerebras CS-2是训练大型语言模型的游戏规则改变者. Cerebras团队最近为该系统开发了新的升级,我们预计这将使训练时间进一步减少, 我们期待着与我们的合作伙伴分享这些好处.
smartR AI的工程师马修·马雷克(Matthew Malek)解释了迄今为止取得的显著成果.
smartR AI是一家总部位于博天堂入口的咨询公司,专门从事人工智能的自然语言处理(NLP)应用. 与EPCC的合作, 英国领先的超级计算和数据科学专业知识中心, 源于EPCC的晶圆级引擎CS-2芯片与NVIDIA RTX-3090图形处理单元(GPU)在训练和微调大型语言模型(llm)背景下的性能比较需求。. 要解决这些问题, 我们对两个处理单元的训练收敛时间进行了比较分析.
硬件比较
我们对设计用于优化并行计算的两种高级硬件设置进行了比较.
首先,我们检查了Cerebras晶圆级引擎CS-2芯片, 值得注意的是其巨大的计算核心规模为850,000个ai优化核心. 该芯片通过有效利用其核心和40gb片上内存来解决深度学习瓶颈, 拥有20 PB/s的内存带宽. 相反, smartR AI Alchemist服务器采用NVIDIA RTX 3090, 将其定位为llm内部微调的有前途的解决方案.
“惊人的”结果
确保公平, 我们将CUDA和WSE核心计数对齐,直接比较训练损失转换性能. 这种面对面的分析揭示了并行计算的可能性, 影响法学硕士和深度学习应用的发展. 结果是惊人的,我们的GPT-2模型的预训练优化速度提高了五倍.
在我们的对比实验中,我们对一个版本的 GPT-2模型. 正如最初的OpenAI GPT2论文所使用的,我们使用了一个开放版本的WebText, OpenWebText,它是WebText语料库的开源重建. 文本是从Reddit上分享的url中提取的网络内容,至少有三个赞(38GB).
我们使用了一个字节对编码(BPE)标记器,词汇表大小为50,000. 然而,我们的GPU硬件限制导致我们将这个数据集的上下文大小保持在512个单位. 这个选择帮助我们在GPU的能力范围内工作,同时仍然有效地服务于目的.
在一项重要的研究中,我们通过预训练一个较小的版本进行了比较 GPT-2模型. 我们参与了一个涵盖150人的全面培训过程,000个训练步骤, 在训练损失收敛的点上达到顶点.
这个特定版本的GPT-2模型拥有1.17亿个参数和512个上下文大小. 使用具有50个词汇表的字节对编码(BPE)标记器,000个单词, 我们通过对模型权重使用完整的float32来保持精度, 这需要512兆的内存分配. 由于我们的GPU的硬件限制, 我们不能创建上下文大小大于1024的模型, 现代法学硕士有哪些.
在整个培训过程中,我们使用了16个批次,并实施了 AdamW优化算法 学习率为2.8E-4,以及学习率调度器.
到目前为止, smartR AI已经成功地在EPCC系统上用Cerebras CS-2芯片在近一个小时内从头开始训练一个模型, 相比之下,在smartR AI自己的内部系统上使用NVIDIA RTX 3090 GPU需要10个小时才能完成. 该公司从事这个项目的工程师非常确定,他们将能够在EPCC的Cerebras系统上利用更多的资源,从而进一步加快速度.
下图是EPCC CS-2服务器与内部服务器GPT培训的对比结果.
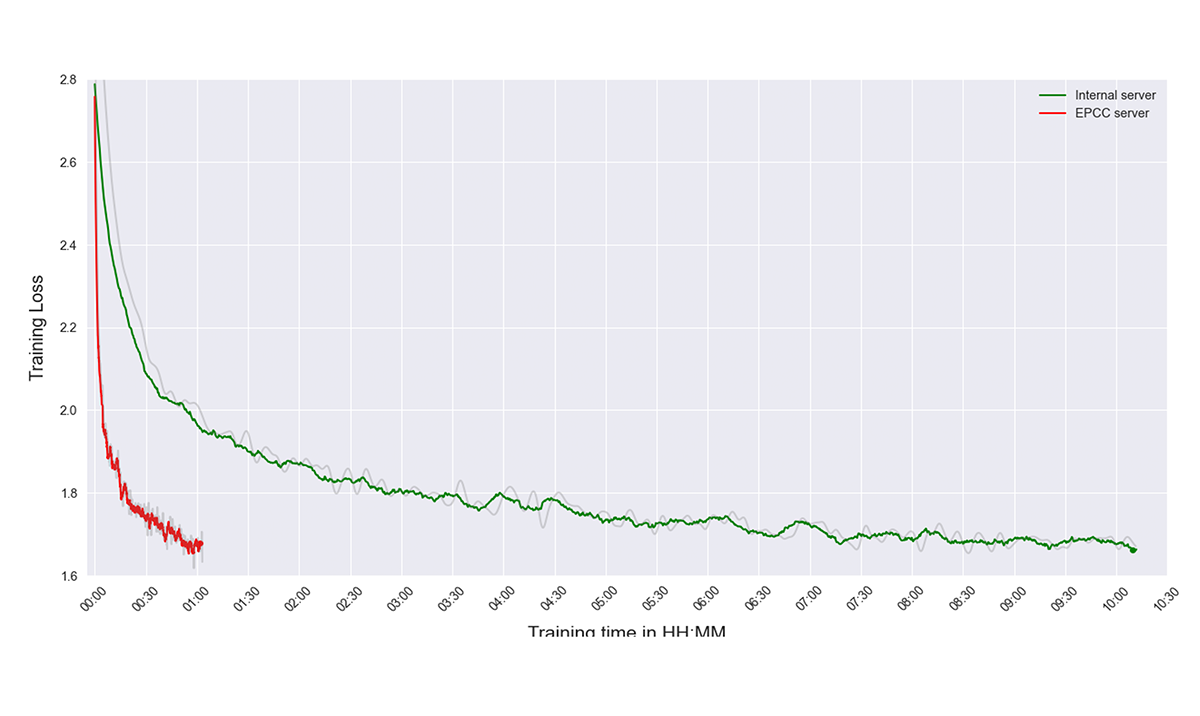
奥利弗King-Smith, smartR AI创始人兼首席执行官, 评论说:“我们非常幸运能够与EPCC在这个重要的法学硕士和GPT相关的性能项目上合作, 并期待将其他类似的测试与, 例如, EPCC的新图core POD64系统.”